|
Administrator
|
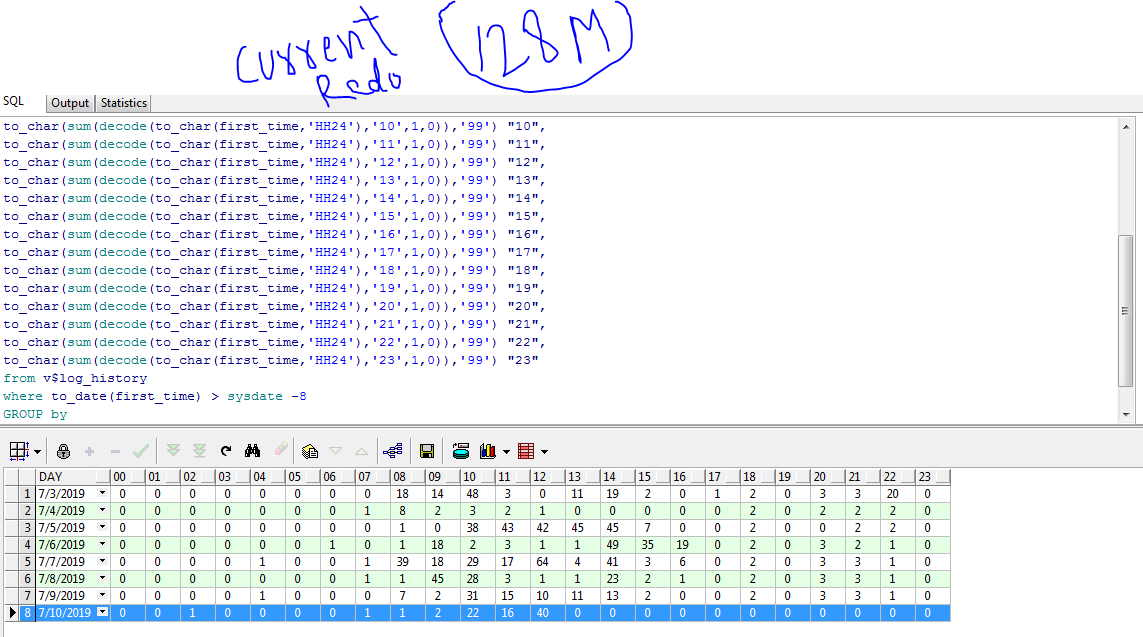
It seems during the day, you have several log switches.
Log switches initiate checkpoints.
Checkpoints mean I/O.
On the other hand, if you have a very big redo size, then you will do checkoints rarely, this means less I/O.
But this time, you will spend more time during instance recovery (when needed).
So you need to find an optimal/balanced value between between the frequency of logswitches and meeting your recovery time requirements.
These lots of log switches may be a problem or not.
You can understand it by taking a look at the alert log, the logs like "checkpoint not complete" or "archive not complete".. If you see these logs, then your log switches are not fine. So you need to decrease the logswitches or increase the performance of your I/O Subsystem.
Similarly, check if your startup times (after shutdown abort for instance) take long time or not..
If it takes long time, then it means you log switch frequency is not as high as needed.. ( this can be controlled by the fast_start_mttr_target parameter)
Understand my point?
So you need to check your environment first..
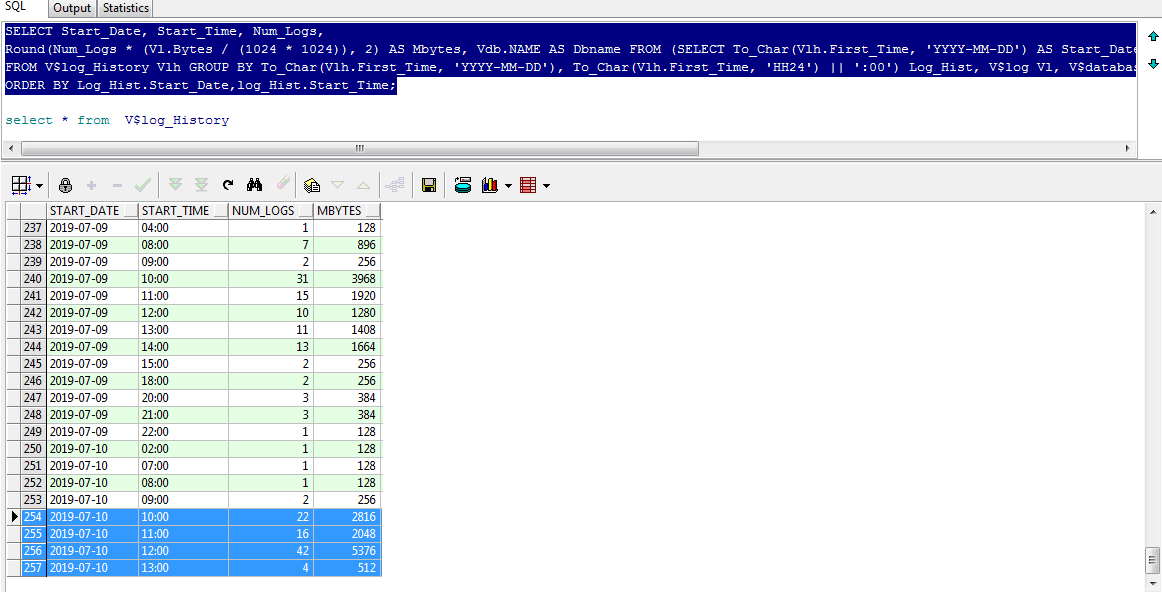
Also we have a MOS document for addressing this -> General Guideline For Sizing The Online Redo Log Files (Doc ID 781999.1)
There is a general instruction written there -> "if your online redo logs (for example) switch once every 5 minutes during peak database activity, to achieve the 20 minute guideline, the logs would each need to be 4 times larger then their current size. (i.e. 20 / 5 = 4)"
Get the idea?
You can also use Recommended Redolog Advisor for getting an optimal value. 10g New Feature: REDO LOGS SIZING ADVISORY (Doc ID 274264.1)
You can also obtain redo sizing advice on the Redo Log Groups page of Oracle Enterprise Manager Database Control.
|